2017년 10월 19일 과학 저널 <네이처>에 '인간 지식 없이 바둑을 마스터하기(Mastering the game of Go without human knowledge)'라는 제목의 논문이 발표되었습니다. 이 논문은 언론에 대대적으로 소개되었고, 논문 제목이 암시하듯이 '인간 지식 없이도' 인공지능이 발전할 수 있다고 소개되었습니다. 과연 알파고는 인간이 생산한 데이터가 정말로 필요 없을까요? 인공지능은 더 이상 인간의 데이터가 없이도 발전할까요?
이 점을 판단하기 위해서는 인공지능의 작동 방식을 잘 알아야 합니다. 인공지능은 일종의 컴퓨터 프로그램입니다. 일반인에게는 '기계학습(머신러닝)'이라는 알듯말듯한 용어가 유행하지만, 사실 인공지능을 만드는 방식은 둘입니다. 하나는 사람이 일일이 코드를 짜는 거고(IBM 왓슨, 쿠쿠, 트롬 등), 다른 하나는 프로그램을 시켜 코드를 짜는 겁니다(알파고, 구글번역, 검색, 음성인식 등). 코드를 짜는 프로그램을 다른 말로 '기계학습 프로그램'이라고 합니다. (그림 참조.) 구글이 만든 '텐서플로(TensorFlow)'와 페이스북이 만든 '파이토치(Pytorch)'가 기계학습 프로그램의 대표주자입니다.
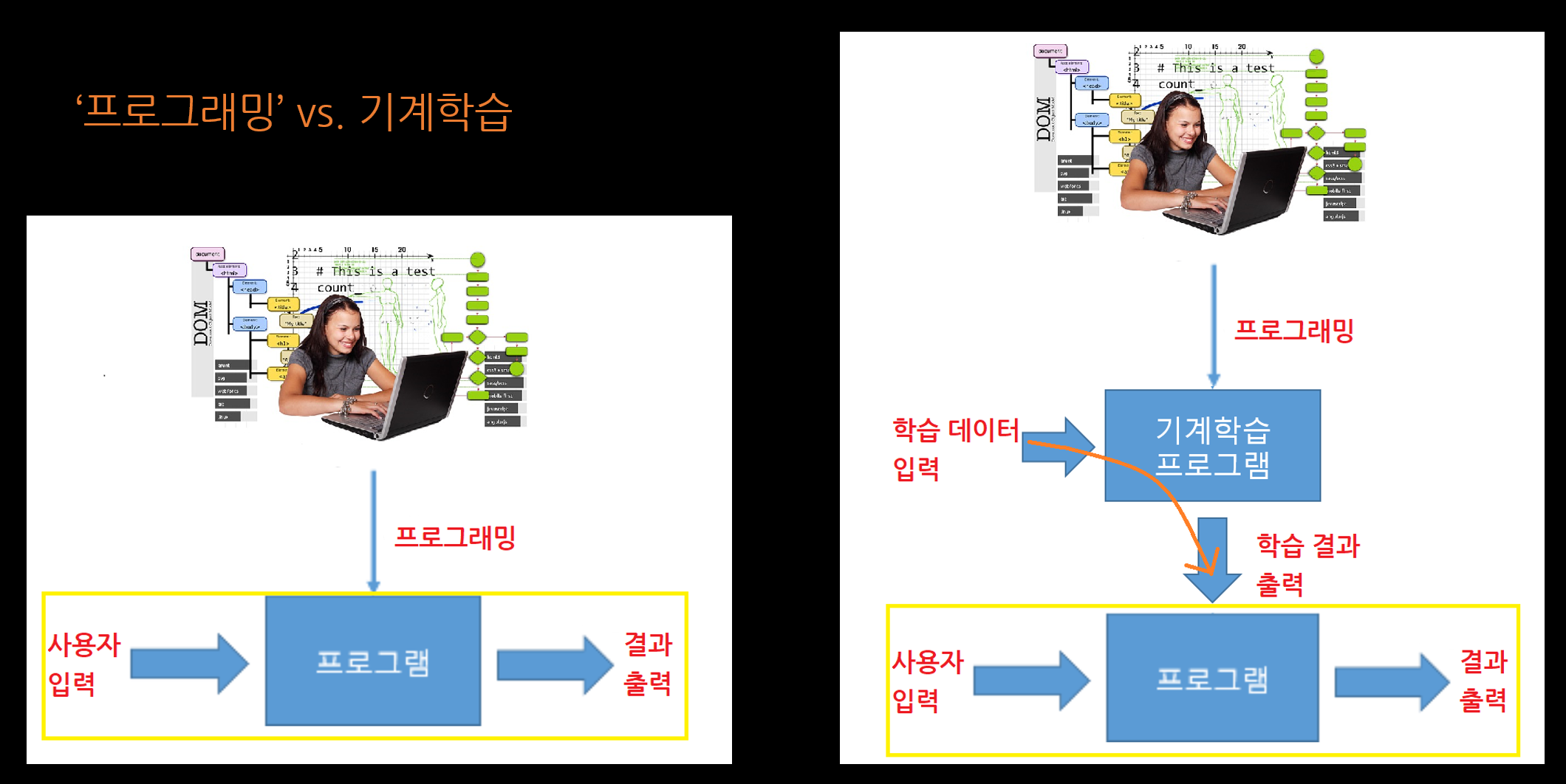
그럼 기계학습 프로그램은 무슨 일을 할까요? 기계학습이란 무슨 뜻일까요? 이 점과 관련해서 한국의 일반인은 커다란 오해에 직면했습니다. 바로 알파고 때문입니다. 한국 사회에 인공지능 열풍이 불기 시작한 건 다 알다시피 알파고와 이세돌의 충격적인 대국 결과 때문이었습니다. 그리고 알파고가 '기계학습'을 통해, 또는 '신경망'을 갖춘 '딥러닝'을 통해 만들어졌다고 이야기되었습니다. 맞는 말이지만 부분적으로만 맞다고 해야 할 겁니다. 왜 그런지 보겠습니다.
기계학습에는 크게 두 부류가 있습니다. '지도학습(Supervised Learning)'과 '강화학습(Reinforcement Learning)'이 그것입니다. '비지도학습(Unsupervised Learning)'이라는 것도 있지만, 아직 갈 길이 멀어서 제외했습니다. 기계학습은 '입력값'과 '출력값' 사이의 패턴, 상관관계, 연결규칙, 함수 등을 찾는 작업을 가리킨다고 요약할 수 있습니다.
지도학습에서 중요한 것은 데이터입니다. 지도학습에서 입력값과 출력값은 모두 우리가 정답을 알고 있는 데이터입니다. 즉, 어떤 입력값이 있으면 그에 대응하는 정확한 출력값이 있다는 식입니다. 1 다음에 3이 왔다, 3 다음에 5가 왔다, 5 다음에 7이 왔다, 7 다음에 9가 왔다... 이런 식으로 {입력값, 출력값}의 쌍이 아주 많이 확보되어 있다고 해 봅시다(이런 걸 '데이터 세트(data set)'이라고 부릅니다). 이 경우 입력값과 출력값을 연결해 주는 규칙은 무엇일까요? 17 다음에 올 수는 무엇일까요? 우리는 이 물음들에 어렵지 않게 답할 수 있습니다. 규칙은 앞 수에 2를 더한다는 것이고, 17 다음에는 19가 올 겁니다. 이런 단순한 추론과 응용은 누구라도 어렵지 않게 할 수 있습니다.
그런데 데이터가 아주 많다고 해 봅시다. 세간에 많이 이야기되는 빅데이터를 떠올려도 좋습니다. 과연 이런 상황에서 입력값과 출력값을 연결해 주는 규칙을 쉽게 찾을 수 있을까요? 사람에게 어려운 그 일을 프로그램을 시켜서 찾게 해 볼 수 있겠지요? 바로 이것이 '지도학습'이라고 불리는 과정입니다. 지도학습에서 가장 중요한 것은 정답을 알고 있는 데이터입니다. 잘못된 데이터가 더 많이 끼어들수록 잘못된 연결규칙을 찾거나 규칙을 찾지 못하거나 할 겁니다. 흔히 데이터가 중요하다고 하지만, 이는 틀린 말입니다. 중요한 것은 정확하고 많은 데이터입니다.
지도학습은 아직 일어나지 않은 상황에서 '예측'과 '추천'을 가능케 합니다. 가령 아마존은 고객들이 생산한 수많은 클릭과 체류시간과 구매에 이르는 데이터를 갖고 있습니다. 그리고 지도학습을 통해 이 데이터로부터 연결패턴을 찾아냅니다. 당연히 고객이 선호할 만한 상품을 예측해서 추천해 주겠지요. 이를 통해 매출은 증가할 수 있습니다. 대부분의 ICT 기업이 인공지능을 통해 하려는 일도 유사합니다. 예측과 추천입니다. 검색 결과를 추천해 주고, 번역 문장을 추천해 주고, 자동차 이동 경로를 추천해 주고, 가까운 기사를 추천해 주고... 이렇게 고객 만족을 통해 이윤을 극대화하는 겁니다.
"지도학습이 현실의 데이터로부터 연결규칙(pattern, function)을 찾아내는 과정이라면, 강화학습은 행동규칙(rule)이 정해진 플레이에서 최선의 수를 찾아내는 것을 목표로 합니다. 가령 중국 바둑 규칙에 따라 바둑을 둔다고 할 때, 매번 둘 때마다 승률이 가장 높은 수를 찾아내는 것이지요. 아니면 스타크래프트에서 최선의 키보드-마우스 조작 방법을 찾는 작업이라 해도 좋습니다. 목표는 최고의 보상(maximaized reward)입니다. 바로 알파고가 최종적으로는 강화학습을 통해 만들어졌지요."
알파고는 한국 사회에 인공지능 열풍을 일으키기도 했지만 심각한 오해도 함께 불어넣어 주었습니다. 강화학습에는 본래 데이터가 필요 없습니다. 그런데 이세돌과 대국한 알파고, 이듬해 중국 기사들과 대국한 알파고는 인간이 생산한 기보를 통해 학습했습니다. 데이터를 사용한 거지요. 그렇게 해서 만들어진 최강자가 '알파고 마스터' 버전입니다. 인간 프로 기사에게 완승을 거두었지요. 한편 중국 바둑 규칙 내에서 마음대로 플레이하고, 승률이 높은 수를 찾도록 하는 훈련을 시켜 만들어낸 것이 '알파고 제로' 버전입니다. 무려 자가대국 2900만 판을 두도록 했습니다. 그리고 역사적 대국이 벌어집니다. '알파고 마스터' 대 '알파고 제로'의 대결. 알파고 제로는 89대 11로 알파고 마스터를 이겼고, 바로 바둑에서 은퇴했습니다.

알파고 개발사 '구글 딥마인드'는 이세돌과 대국을 벌인 2016년에는, 본래 데이터 없이 최고 보상을 찾도록 하는 '강화학습 형 기계학습'과 데이터가 필요한 '지도학습 형 기계학습'을 섞어서 사용했지만, 2017년에는 '데이터 없이도' 인공지능이 만들어질 수 있다는 것을 보여주었습니다. 알파고는 처음부터 인간 기보 없이 만들어질 수 있었고, 오히려 인간 기보에 포함된 나쁜 데이터가 장애 요인이 됐습니다. 이제 더 이상 인간이 생산한 데이터가 필요 없는 인공지능이 등장했다는 오보는 강화학습과 지도학습을 혼동한 데서 비롯됐습니다. '알파고'라는 이름이 계속 사용되었기 때문에 생긴 문제이기도 합니다.
알파고는 '신경망'을 갖춘 '딥러닝'을 통해 만들어진 인공지능인 건 맞습니다. 하지만 이런 용어들은 요즘의 모든 기계학습 프로그램의 작동 원리이기도 합니다. 더 중요한 건 기계학습 중에서 '지도학습'과 '강화학습'의 구별입니다. 지도학습은 데이터 분석에 기반한 규칙 파악이 중요하고, 강화학습은 데이터가 필요 없이 규칙에 따른 플레이에서의 최대 보상이 중요합니다. 알파고는 데이터 없이 개발될 수 있는 '강화학습' 기반 인공지능입니다. 처음에 데이터를 통해 학습했던 건 연구 초기 단계였기 때문에 어쩔 수 없었을지라도, 혼동의 여지를 제공한 건 분명 문제입니다. 딥마인드건 언론이건 오해를 바로잡았어야 한다고 봅니다.
지금까지 인공지능 판사의 문제를 다루기 위한 기초 지식을 다져봤습니다. 끝내기 전에 한 가지 꼭 짚고 갈 점이 있습니다. 기자들 공부 좀 많이 합시다. 아울러 기자들의 잘못된 보도에 넘어가지 않으려면 독자들도 공부를 많이 한 '깨어있는 시민'이 되어야 합니다.
*2018년 9월 18일 오후 1시 30분 수정: 일부 단정적인 표현으로 오해를 불러 일으켜 7, 9, 10번째 문단 내용 및 부제목 수정.